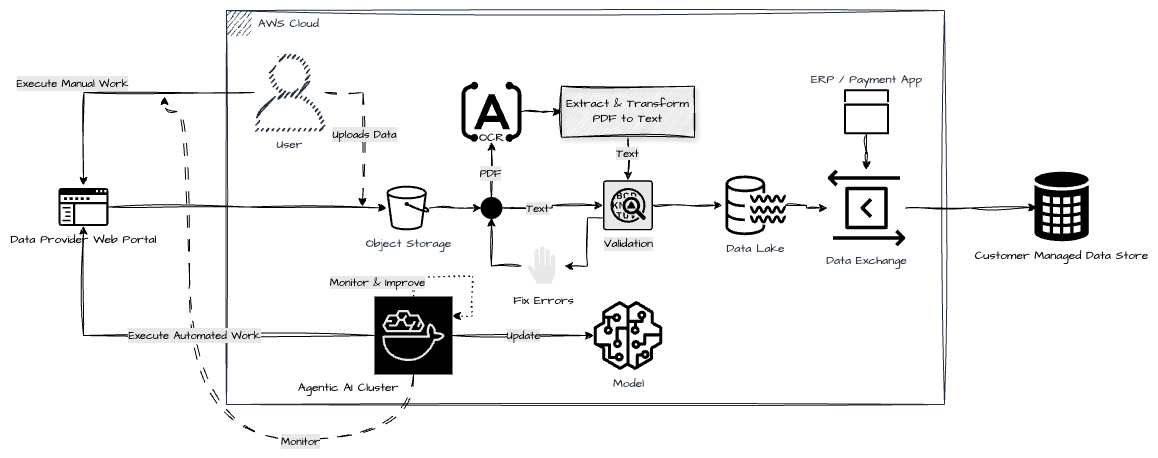
Agentic AI RPA Process
This architecture diagram depicts an automated data ingestion and processing pipeline that leverages both manual and automated workflows, with a focus on OCR, validation, and AI-driven improvement loops, all operating within the AWS cloud. Below is a step-by-step breakdown of each component and the AWS native services you would likely use to implement it:
🔁 Flow Breakdown
1. Data Ingestion (Manual and Automated)
Manual Work (User): A user manually logs into a data provider web portal and uploads claim data (typically PDFs).
Automated Work (Agentic AI Cluster): Agentic AI automates portal interactions to download files and push to object storage.
AWS Services:
Amazon WorkSpaces or EC2 – for browser automation by AI agents (Selenium, Playwright).
AWS Transfer Family or API Gateway + Lambda – if data is being uploaded via SFTP or custom APIs.
Amazon S3 – used as the object storage bucket for raw file uploads (PDFs/text).
2. Storage
Files from users and AI agents are stored in S3 (Object Storage).
AWS Services:
✅ Amazon S3 – Durable, scalable, and cost-effective storage for raw PDFs and text files.
3. OCR (PDF to Text Conversion)
Files in PDF format go through an OCR process to extract textual data.
AWS Services:
Amazon Textract – For OCR and structured data extraction.
Amazon Rekognition (optional) – For image analysis if needed.
AWS Lambda or AWS Fargate – To run open-source OCR stacks like Tesseract and GraphicsMagick.
4. Extract & Transform
The OCR output is transformed from raw text into a structured format suitable for processing.
AWS Services:
AWS Glue – For extract-transform-load (ETL) jobs.
AWS Lambda – For lightweight transformation logic.
Amazon Step Functions – To orchestrate complex transformation workflows.
5. Validation
The text data is validated for structure, completeness, and correctness.
AWS Services:
AWS Lambda – For rule-based validation.
Amazon SageMaker – For ML-driven anomaly detection or classification (e.g., fraud, missing fields).
Amazon SQS / EventBridge – To queue validation jobs or route based on results.
6. Data Lake
Validated data is stored in a centralized lake for analytics or downstream integration.
AWS Services:
✅ Amazon S3 (again) – As the backing store for your data lake.
AWS Lake Formation – To manage access and catalog metadata.
Amazon Athena – To query the data lake using SQL.
AWS Glue Data Catalog – To register and discover datasets.
7. Data Exchange to ERP/Payment Apps
Data is sent to ERP or payment apps and customer-managed data stores.
AWS Services:
AWS Data Exchange – If external data sharing is required.
Amazon AppFlow – For secure, bidirectional data flow with SaaS apps like SAP, Salesforce, etc.
Amazon EventBridge / Step Functions – For orchestration and integration with ERP endpoints.
Amazon API Gateway + Lambda – For custom APIs to communicate with ERP apps.
8. Customer Managed Data Store
Final destination of cleaned and validated data.
AWS Services:
Amazon RDS / Aurora / DynamoDB – Depending on structure, this could be a relational or NoSQL store.
Amazon Redshift – For customer-facing reporting or warehousing.
9. Monitoring, Error Handling, Model Updates
Agentic AI Cluster observes errors and improves the model via updates.
Errors can be fixed manually or fed back into a model improvement loop.
AWS Services:
Amazon CloudWatch – For logs, metrics, and alerting.
Amazon SageMaker – For retraining ML models.
AWS Step Functions – To automate error-handling workflows.
Amazon SNS / SES – To alert human reviewers for errors needing manual intervention.
✅ Key Strengths of the Architecture
Hybrid Manual-Automation Design: Resilient in environments with partial automation capability.
Event-Driven & Serverless: Reduces cost, complexity, and idle compute waste.
Scalable: Can easily support many customers/entities with this modular setup.
Closed-Loop Learning: Model improvements are fed back from observed failures.