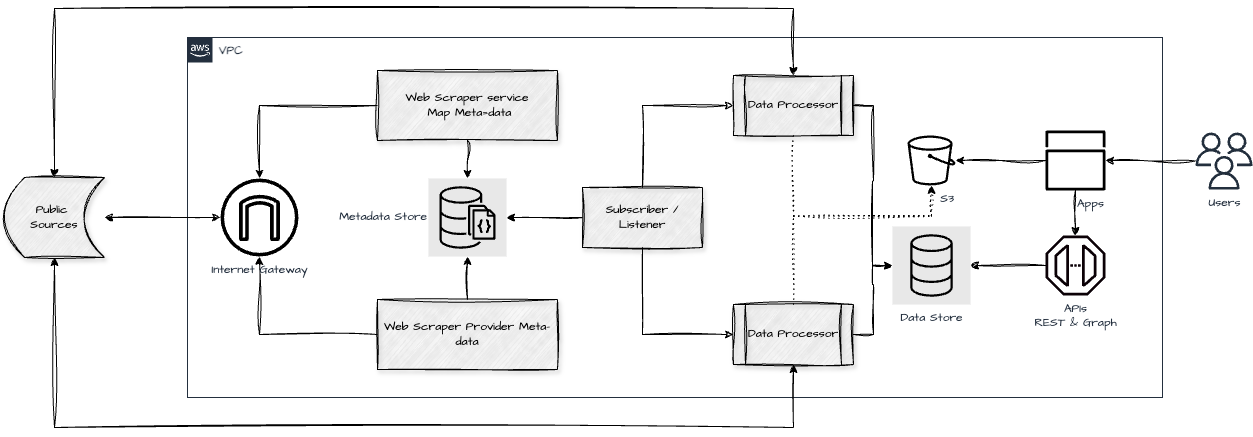
Web Scraper & Content Publishing System
This architecture diagram represents a public data ingestion and processing pipeline powered by web scraping and downstream data processing, ultimately serving users via apps and APIs.
🧠 Use Case
A system that:
Collects metadata and structured data from public sources (web scraping).
Stores and processes this data in real-time or near-real-time.
Makes data available to end-users through web/mobile apps and APIs.
Use cases might include:
Competitive intelligence (e.g., monitoring public product listings or pricing).
News or event aggregation.
Market sentiment analysis.
Public health or government data tracking.
🧱 Modern AWS Technologies Mapping
1. Public Sources + Internet Gateway
NAT Gateway: Egress point for resources running inside the VPC.
2. Web Scraper Service (Map Metadata / Provider Metadata)
AWS Lambda or Fargate: Stateless scraping functions.
AWS Step Functions: For orchestrating scraping workflows.
Amazon CloudWatch Events / EventBridge: For scheduled scraping.
For more advanced scraping:
Amazon EC2 Spot Instances or ECS with Fargate: For heavy-duty scraping tasks requiring headless browsers (e.g., Puppeteer with Chromium).
Use Tor or proxies via 3rd-party VPC peering or NAT traversal if needed.
3. Metadata Store
Amazon DynamoDB: For storing semi-structured metadata from scrapers (fast lookups, JSON support).
Amazon S3: For raw HTML or JSON blob storage.
4. Subscriber / Listener
Amazon EventBridge or Amazon SNS/SQS: To notify when new metadata is stored or a scraping job is complete.
AWS Lambda: Acts as the subscriber/trigger to launch data processors.
5. Data Processor (x2)
AWS Glue or AWS Lambda: For cleaning, transforming, or enriching data.
Amazon EMR or AWS Batch: If heavy ETL or analytics is needed.
6. S3 + Data Store
Amazon S3: For storing processed data, reports, or ML training sets.
Amazon Aurora (PostgreSQL) or Amazon DynamoDB: For structured and relational access.
Amazon OpenSearch: If full-text search or analytics are required.
7. Apps + APIs
Amazon API Gateway: To expose REST or GraphQL endpoints.
AWS AppSync: For managed GraphQL APIs.
Amazon Cognito: For authentication and user management.
AWS Amplify or Amazon CloudFront + S3 Static Site Hosting: For serving frontend apps.
🧩 Optional Enhancements
Monitoring: Use Amazon CloudWatch and X-Ray for observability.
Security: Leverage AWS WAF, Shield, and IAM roles for access control.
Cost optimization: Use AWS Compute Optimizer, Savings Plans, and S3 lifecycle policies.